

ありがたいことに、弊社製のストレージサーバーは様々なお客様の元で運用いただいていますが、設置環境や使用状況によっては、ハードディスクドライブ(HDD)の故障率が体感的に他と比べて高いと思われる環境もあります。そこで、同時期に納入し、保守契約を締結している3拠点で使用しているHDDについて、3年間の運用を通して、S.M.A.R.T.値の増加傾向や、交換状況をまとめてみました(データを使用させていただくことはご了承済みです)。
ストレージシステムの運用において、どの程度保守用のディスクやコストを見ておけば良いか、運用の参考になればと思います。
ストレージサーバー 1台あたりの構成
| 使用ハードディスク | Seagate Constellation ES 7200rpm 32MB ニアラインHDD(※注1) Cドライブx1台、データドライブx11台 ※使用ディスクは全てスクリーニング(選定試験)済みです。 |
| 筐体 | Supermicro SC826TQ-R800LPB(2Uラックマウント) |
※注1:ニアラインとは、頻繁にアクセス・書き換えが行われるされるサーバ向けストレージ「オンライン」と、データの長期保存向けストレージの「アーカイブ」の中間を意味し、ニアラインHDDは一般的なデスクトップ向けHDDよりも信頼性を重視した設計が行われている。
使用環境について
・サーバールームの温度は26℃程度で安定。
・すべて同シリーズのHDDを利用。
・各HDDへのアクセスはランダムかつ、24時間365日稼働。
・運用監視期間は2011年3月~2014年3月の約3年間。
監視対象の各拠点の状況
| 構成 | 各ディスクにかかる負荷 | |
| 拠点A | HDD12台xサーバー12台 | 毎日平均2G~4GB程度の読み書き、削除あり |
| 拠点B | HDD12台xサーバー4台 | 毎日平均0.6GB程度の読み書き、基本追記のみ |
| 拠点C | HDD7台xサーバー4台 | 毎日平均0.2GB程度の読み書き、基本追記のみ |
ディスク交換の状況
2011/3~2014/3の約3年間でのHDD交換対応履歴です。
| 拠点A (144台中、16台交換) | 筐体 | 交換履歴 |
| ストレージ 1 | ディスク4台交換 | |
| ストレージ 2 | 交換なし | |
| ストレージ 3 | 交換なし | |
| ストレージ 4 | ディスク2台交換 | |
| ストレージ 5 | ディスク4台交換 | |
| ストレージ 6 | ディスク1台交換 | |
| ストレージ 7 | ディスク1台交換 | |
| ストレージ 8 | 交換なし | |
| ストレージ 9 | ディスク1台交換 | |
| ストレージ 10 | ディスク1台交換 | |
| ストレージ 11 | ディスク1台交換 | |
| ストレージ 12 | ディスク1台交換 |
| 拠点B (48台中、1台交換) | 筐体 | 交換履歴 |
| ストレージ 1 | 交換なし | |
| ストレージ 2 | 交換なし | |
| ストレージ 3 | 交換なし | |
| ストレージ 4 | ディスク1台交換 |
| 拠点C (28台中、交換なし) | 筐体 | 交換履歴 |
| ストレージ 1 | ディスク4台交換 | |
| ストレージ 2 | 交換なし | |
| ストレージ 3 | 交換なし | |
| ストレージ 4 | ディスク2台交換 |
上記の交換履歴は完全な故障ではなく、故障可能性が高まった状態での予防的な交換を含みます(後述)。使用しているHDDのMTBF(平均故障間隔)は140万時間=159.7年とされているため、単純計算した限りでは、HDDを100台使用して24時間365日稼動した場合に1年で0.626台故障するということになります。その数字をもとにすると、12ストレージ(HDD 144台)であれば、3年で約3台故障すると予想することができます。
扱うデータ量の差、読み書きの発生量、台数の違いがあるので、一概には比較できないのですが、MTBF値から考えると、拠点Aの交換率は予想より高いと言えます。使い方や環境により故障率が左右される面も大きそうです。なお、故障の前兆が出た段階で予防的に交換しているHDDも多く、実際に故障レベル(認識しない)に達してから交換したものは全部で3台です。
故障・交換ディスクのS.M.A.R.T.値変動…「Reallocated Sector Ct」
交換に至ったディスクでは、S.M.A.R.T.値の「5 Reallocated_Sector_Ct(代替処理済みの不良セクタ)」の数値に変動がみられました。以下では故障して交換したケース、故障に至る前に予防的に交換したケース、それぞれの代替処理済みセクタ数の推移をグラフ化してみました。監視期間中、この値以外に故障予測に影響するようなS.M.A.R.T.値の動きは確認できませんでした。
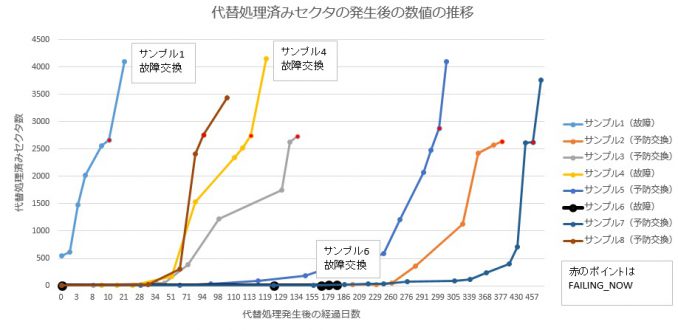
FAILING_NOWについて
通常、S.M.A.R.T.値は下記のようにデータが表示されますが、「VALUE(現在の値)」の見出しの下に表示されるNormalized値(正規化値)がしきい値を下回ると、「WHEN_FAILED」見出しの下に「FAILING_NOW」が表示されます。「FALING_NOW」が表示されたら、しきい値を下回った危険な状態と言えます。
考察と補足
結論を導くにはデータの絶対数が少ないため、あくまで目の前の事象に対する考察となりますが、現在のところ、以下のようなことが考えられます。
◆FAILING_NOWまで至ったディスクの「5 Reallocated_Sector_Ct」の数値変化の曲線はどれも類似している。1か月の間に数値が急激に増加する(数百を超える数値が記録される)場合、その後、数か月~半年のうちにはしきい値を下回り、故障まで達する可能性が高いと考えられる。
◆認識しない状況になったHDDは、FAILING_NOWが発生した後、約1週間程度で認識しなくなった。
◆サンプル6のようにS.M.A.R.T.値に関係なく、突然故障してしまうこともある。
◆環境や使用頻度による違い
そもそものデータ読み書き頻度の違いがあるということのほか、A環境では常時インバーター方式のUPSを利用していますが、土地柄、電圧変動が激しく、さらに計画停電を頻繁に実施しているため、電源のON/OFFがたびたび発生しています。これが直接的にHDDへのストレスとなっているかどうか、断言はできないのですが、B、C環境との違いの一つとして挙げられます。サーバーは常時稼働を前提として設計されているため、あまり望ましくない環境と考えられます。
◆HDDやその他の部品の品質のばらつき
拠点AとB、Cの納入時期が若干ズレているため、製造ロットによる違いもあるかもしれません。また、2011年3月~2014年3月の計測期間中、ディスク交換を実施したのは2012年がほとんどでした。その時期を生き残った(?)ディスク及び、交換後のディスクは今のところは目立った代替セクタの増加は見られておりません。
◆今回はニアラインHDDを利用したデータですが、コンシューマ向け及び、特殊用途のHDD、SSD等と比較してどうなのか、今後まとめてみたいところです。
あとがき
これまでの経験上、FAILING_NOWが発生したものは、その後平均して1週間程度を目途に認識しなくなるという結果となっています。また、代替セクタに関しては、緩やかに増加し総計が1000を超える数が発生していたとしても、認識しないというレベルになるまで、かなりの時間を要することがあります(ある意味、正常に代替セクタの割り当てに成功しているということから、正常に動作している、という見方もできるかと思います)。弊社ではこの辺りのデータを交換時期の参考の一つとしています。
上記サーバーの運用においては、代替セクタの増え方があまりにも早いといった場合や、FAILING_NOWが発生した場合等には、予防交換を実施することとしております。ただ、S.M.A.R.T.値に何ら異常がない場合でも、急に認識しなくなった、何か動作が怪しい、といったことはあり得ますので、S.M.A.R.T.値を過信するのも考え物です。
S.M.A.R.T.値は、ディスクの故障が運用上、どこまでクリティカルな問題となるのかということを考慮し、あくまで一つの参考として、未然の故障に備えるために利用する、という活用の仕方が向いているかと思います。S.M.A.R.T.値の変化に対する対応策の基準を定めたうえで運用することができれば、無用なトラブルは減らせるのではないかと考えております。